This is a summary of my session “Code best practices and performance optimization” that I held during Episerver (still trying to learn the new casing format) Ascend 2015 in Las Vegas and the Episerver Tech forum in Stockholm.
The session mentions in three areas some fundamental tips and tools on profiling your solution and how you can work with the Episerver CMS API.
- Tools
- Distractions
- Scenarios
- SessionState
- Loading Content & Episerver API
- Cache
- Race Condition Locks
So let’s begin!
Tools
Here are some of the tools I used in my session to see what ails my application.
DotTrace
DotTrace from JetBrains is a cool tool that we use alot at NetRelations to monitor CPU and memory usage as well as keeping track on method calls and time in your application.
It has a quite high cost so you can find some other options such as the built in profiling tool in Visual Studio which is getting better through each version or ANTS Performande Profiler from Redgate.
However JetBrains are continously improving their tool continously and with their new Timeline reports I find it really useful keeping track of HttpRequests, SQL requests among other things!
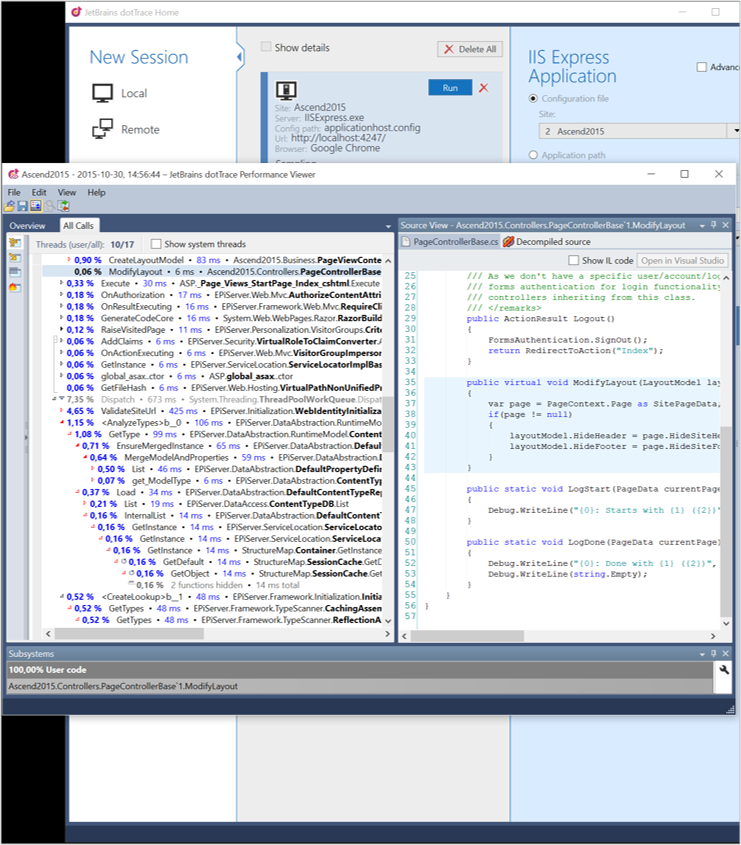
SQL Server Profiler
Microsoft’s own SQL Server Profiler gives you a great overview about what’s going on at your SQL Server. It monitors database requests and can give you an overview about performance as well.
I would recommend that you’re using SQL Server Profiler in production environment with caution. It’s mostly in production you can get the best trackings but it can lower performance while profiling.
Distractions
While profiling your solution you want to focus on your pain points without any distractions. Otherwise it would be like a doctor investigating pains in a knee while someone is hurting the patient’s arm.
The easiest ways to reduce this in an Episerver solution is to disable scheduled jobs and to focus your Http requests.
Scheduled Jobs
Meanwhile you’re trying to profile your solution, you don’t want any unecessary activities. Here’s where Episerver’s Scheduled jobs can be quite annoying! But it’s very easy to deactive in web.config by setting enableScheduler to “false” on the episerver/applicationSettings element.
<configuration> <episerver> <applicationSettings enableScheduler=“false” /> </episerver> </configuration>
Frontend resources
While you’re using a browser to visit pages in your Episerver site, your browser will create more requests to download resources such as JavaScript and Stylesheets. Modern browsers also want to find a /favicon.ico file on the server.
More importantly the browser downloads images embedded in the page. As you probably know, images in Episerver are managed as content where each request will use the Episerver CMS Api and in turn make requests to the database.
Some tools that can be used to focus on your specific functions are creating a .NET Command Line based solution, but better up using LINQPad – a nifty feature where you can “code” simple C# code without creating an entire Visual Studio project.
Another useful tool for creating single custom Http Requests are the Chrome plugin Postman.
Personally I like LINQPad since you can do more things than only Http Requests, such as firing multiple ones at the same time using the script Ascend product pages.linq that I used while profiling with DotTrace.
Scenarios
I will now present some profiling scenarios and explain why I recommend that you try to avoid them.
In the code, found on my GitHub repository I have created a specific Interface called IStandardPageRepository. The purpose is to list StandardPages that are descendants to a specific page. I’m using this on a ProductPageController that I have added to a normal Alloy website. To test the performance I have also created a nested tree structure of StandardPages beneath each Product Page in the Alloy website – Alloy Meet, Alloy Track and Alloy Plan.
The implementation of IStandardPageRepository is registered using the ServiceConfigurator attribute and fetched by injecting it in the constructor of my ProductPageController.
SessionState
Using SessionState is a lovely feature where you can save information for the visitor between each request. However it has some faults that makes the website is perceived as slow. This is because .NET queues up each request from the same visitor so that Session information is synched between each request. This includes AJAX requests as well as the behavior of many visitors today where they might run your website in multiple tabs.

This is quite easy to fix by either adding the attribute [SessionState(SessionStateBehavior.Disabled)] to your MVC Controller or the attribute EnableSessionState=”false” to your WebForms registration directive.

So what about your beloved Session information? Do you really need them? Try to build your solution so that you’re not depending on that kind of information between requests.
An approach I usually have is to stare a “session key” as a cookie and to store the information, such as the shopping cart, on the server. Just keep regional laws about what you’re allowed to store and require to inform your visitor in mind.
Also remember that third party add-ons and features such as some Visitor Groups might require SessionState to be enabled.
Cut to the Code
In the EmptyStandardPageRepository I have added a Thread.Sleep for 2 seconds to simulate a slow page request. By adding the SessionState attribute to the ProductPageController you can see the difference of having SessionState disabled by running your Alloy website and opening two of the Product Pages in separate tabs
Loading content and Episerver API
The most common function we use in Episerver is to load content in different fashions. I will go through some of the functions in the Episerver API and some pros and cons about them.
GetChildren
GetChildren might be one of the most used function in the Episerver API. It’s very easy to use and has some built in features to filter on Content Type and language.
However you’ll need to filter by access rights manually and whatever requirements you’ll have to select your content.
If you have a nested structure you’ll also need to recurse GetChildren for each and every child you find.
This can be seen in the GetChildren implementation of IStandardPageRepository. Here I’m only checking whether each content is a StandardPage but if you have more complex requirements this could be quite expensive.
GetDescendants and Get
Using GetDescendants in Episerver gives you a way to make a single request to receive a list of each and every descendent content.
However this returns a bunch of ContentReference instead of the actual Content, which can be used by the IContentLoader.Get method.
You’ll also need to check access rights and whatever requirements you’ll have which might make it quite expensive.
You can see an example of this in my implementation of IStandardPageRepository called GetDescendantsGet.
GetDescendants and GetItems
Not to forget that if you’re having a bunch of ContentReferences, you don’t need to iterate through these and run the IContentLoader.Get for each ContentReference.
Using IContentLoader.GetItems you can easier get each Content back. However you still need to check access rights and your other requirements about each content that might get expensive.
You can see more about this on the implementation GetDescendentsGetItems.
FindPagesWithCriteria
Here I’ll start focus on database requests and caching by looking at FindPagesWithCriteria which I think is a missunderstood function in Episerver.
It’s not a very precise feature which unfortunately only works with Pages at the moment. But if you have some basic requirements to get your content it works as a charm.
Looking at the implementation called FindPagesWithCritera you’ll find how I’m creating a criterion to find all pages that are Standard Pages.
Just don’t forget to cache the result since it will ALWAYS ends up in a database request using the stored procedure netPropertySearchValueMeta.
Caching
In Episerver you can find two Interfaces that concerns caching, IObjectInstanceCache which in its default implementation wraps HttpRuntime.Cache and ISynchronizedObjectInstanceCache which use IObjectInstanceCache and adds some synchronization to a Load Balanced environment.
ISynchronizedObjectInstanceCache is also found with EPiServer.CacheManager but of course we’d rather prefer using Interfaces and Episerver’s IOC management.
var cache = ServiceLocator.Current.GetInstance<ISynchronizedObjectInstanceCache>(); cache.Insert(key, value, cacheEvictionPolicy);

You can also work with a CacheEvictionPolicy to determine when the cache should be cleared. It could either by how long it should be stored in the cache, or set a dependency on other cache keys.
new CacheEvictionPolicy(new string[] { "cacheKey" });
The main difference between common cache keys and master are that master keys are not required to exist in the cache while cache keys do
new CacheEvictionPolicy(
null, // for files
null, // for cacheKeys
new string[] { "masterKey" });
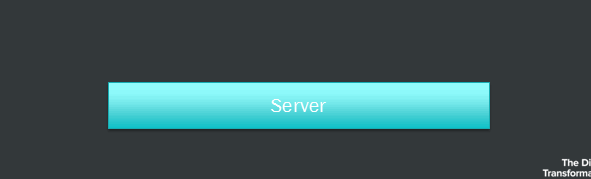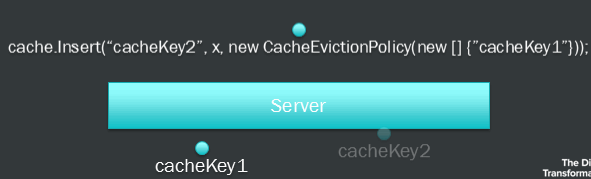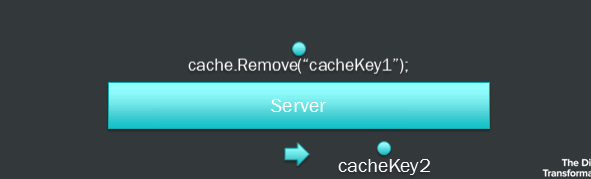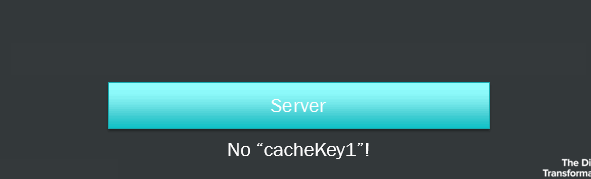
You can see how I’m caching the result of my CachedFindPagesWithCriteria, as you can see I have also added a Thread.Sleep and this will be covered in my next scenario about Race Condition Locks.
In a real world sitation it’s a more common practice to cache the ContentReference instead of the actual Content so that the editor won’t need to wait for the cache to expire for their updates to show, or that you’ll need to write unecessary cache clearing mechanisms.
Race Condition Locks
As mentioned previously, there’s a strange Thread.Sleep before I’m adding the PageDataCollection into the cache. This is to simulate that something is taking an amount of time to perform which might lead to things being run even if they shouldn’t.
Having SQL Profiler monitoring your database and running the LINQPad script Ascend Product pages cached.linq will show you that the first 2 requests are running the stored procedure netPropertySearchValueMeta twice while the third one doesn’t due to the result being cached.
Some resources can also lead to an Exception if two threads (for example two visits your your IIS application) are trying to access it.
Simple lock
Here is where Locking can come handy. The simple version is a simple Lock that makes sure that the second threads waits until the first are finished, and in my example also has stored the result in the cache. You can see an example of this in LockingFindPagesWithCriterion.
Note that after the lock I’m checking the cache again and that is because the locked threads needs to take another look in the cache after they’ve been waiting for the first one to perform its work and cached it.
A bad side in my example is that other threads that will need to perform the implementation of LockingFindPagesWithCriterion based on another root node needs to wait for the first ones to finish before they can do their work.
This can be seen with the LINQPad script Ascend Product pages cached 2.linq.
Mini locking
This is where we can add a more granular locking mechanism by using mini locking.
Instead of having a static object as a lock, we’re using a ConcurrentDictionary<string, object> as a collection of locks. ConcurrentDictionary is a thread safe version of the dictionary and works good for this as you can see in the implementation MiniLockingCachedFindPagesWithCriterion.
Wanna play?
If you want to play around with the code examples from my session, you’ll find them on the GitHub repository https://github.com/alfnilsson/ascend2015. You can also find my presentation as PDF here.
These are just some basic steps to start improving and monitoring your solution. If you have other tips or tools that you use to on how to improve performance, feel free to comment this post.
